Mac用户都应该知道 苹果芯片正在快速崛起。无论是从配置还是从其他方面,苹果在超越自己的同时也远远地把同行甩在后面。本文将详细解答:为什么苹果的M1 运行速度会如此之快?一起来跟小编了解了解吧~

在现实世界一次又一次的测试中,M1 Macs 不仅超越了顶配的英特尔 Mac,而且还彻底击垮了这些电脑。很多人都觉得不可思议,他们开始探究这到底是怎么回事。如果你也持有这样的疑问,那么你来对地方了。在本文中,我将深度剖析苹果的 M1 芯片。具体来说,我认为很多人都持有以下疑问:- 对于英特尔和 AMD 等竞争对手来说,采用相同的技术是否也很容易?
当然,你可以在网上搜索这些问题的答案,但如果你想深入了解苹果所做出的努力,那么可能很快就会被高度专业的技术术语淹没。例如 M1 使用了非常宽的指令解码器、重排序缓冲区(ROB)等等。除非你非常了解 CPU 硬件,否则大多数文章对你来说都是天书。为了方便理解,下面我来简要介绍一下有关 M1 芯片的基础知识。
什么是微处理器(CPU)?
通常,我们谈论的英特尔与 AMD 芯片指的都是中央处理器(CPU),或称微处理器。这些芯片从内存获取指令,然后按照顺序执行每条指令。
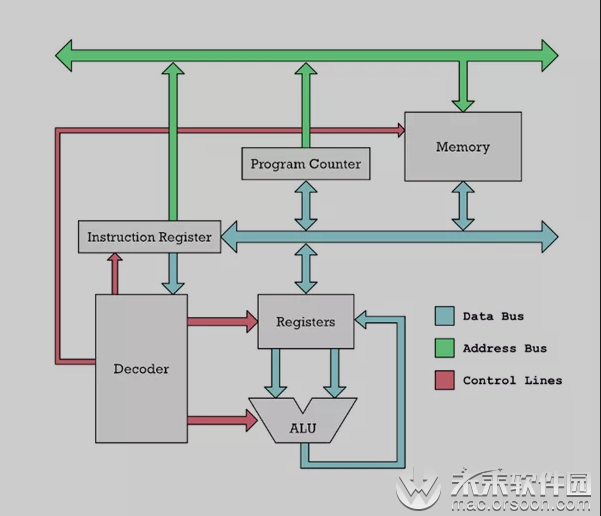
指令从存储器(memory)沿蓝色箭头移动到指令寄存器(register),然后由解码器(decoder)解析指令,并通过红色控制线启动CPU的不同部分,最后由运算器(ALU)将寄存器中的数字相加或相减。最基本的CPU包含一系列寄存器(register)和若干运算器(ALU),其中寄存器是命名的存储单元,而运算器则是计算单元。ALU 可以执行加法、减法以及其他基本数学运算之类的操作。但是,ALU 只连接到 CPU 寄存器。如果要想执行两个数字相加的运算,则必须从内存中获取这两个数字并放入 CPU 的两个寄存器中。以下是 M1 上的 RISC CPU 执行的一些常见的指令示例:
- load r1, 15
- load r2, 200
- add r1, r2
- store r1, 310
上述 r1 和 r2 就是我们所说的寄存器。现代 RISC CPU 无法针对位于寄存器之外的数字进行这样的操作。例如,它不能将内存中两个不同位置的数字相加。相反,它必须将这两个数字放入单独的寄存器中。这就是上述示例中的前两条指令。我们从内存地址 150 中提取数字,并将其放入 CPU 的寄存器 r1 中。接下来,我们将地址 200 中的数字放入寄存器 r2 中。只有这样,两个数字才能通过指令 add r1,r2 相加。
拥有两个寄存器、累加器和输入寄存器。现代 CPU 通常拥有十几个寄存器,而且是电子的。寄存器的概念很早以前就有了。例如,在上图的旧式机械计算器中,寄存器是保存两个加数的地方。寄存器就是存放数字的地方。
M1 不是 CPU!
M1 不是 CPU,它是一个集成了多个芯片的整体系统。而 CPU 只是其中一个芯片。简单来说,M1 就是将一台完整的计算机集成到了一个芯片上。M1 包含 CPU、图形处理单元(GPU)、内存、输入和输出控制器以及构成一台整体计算机的许多其他组件。这就是我们所说的单片系统(System on a Chip,即SoC)。
如今,购买英特尔或 AMD 的芯片时,实际上你得到的是一个封装了多个微处理器的芯片。过去,计算机的诸多芯片会分散加载到主板上。
 内存、CPU、显卡、IO 控制器、网卡以及许多其他组件都连接到了主板上,可以相互通信。
内存、CPU、显卡、IO 控制器、网卡以及许多其他组件都连接到了主板上,可以相互通信。
然而,由于如今我们能够在一块硅片上放置非常多的晶体管,因此英特尔和AMD等公司纷纷开始将多个微处理器集成到一个芯片上。我们称这些芯片为CPU核心。一个核心基本上就是一个完全独立的芯片,可以从内存中读取指令并执行计算。
长期以来,要想提高性能,只需添加更多通用 CPU 核心即可。然而,如今情况发生了变化,CPU 市场的一位商家开始偏离这种趋势。
苹果的异构计算策略并没有那么神秘
苹果并没有选择增加通用 CPU 核心,他们采取了另一种策略:添加越来越多专用芯片来完成一些专门的任务。这样做的好处是,与通用 CPU 核心相比,专用芯片能够更快地完成任务,而且耗电量更少。这不是一个全新的做法。多年来,英伟达和 AMD 的显卡中都搭载了图形处理单元(GPU)等专用芯片,这些芯片执行与图形相关的操作要比通用 CPU 快许多。苹果所做的只是更大胆地朝这个方向转变。M1 不仅具有通用核心和存储器,而且还包含各种专用芯片:- 中央处理单元(CPU):单片系统的大脑。负责运行操作系统和应用程序的大多数代码。
- 图形处理单元(GPU):处理与图形相关的任务。例如显示应用程序的用户界面,以及 2D/3D 游戏等。
- 图像处理单元(ISP):可用于加速图像处理应用程序的常见任务。
- 数字信号处理器(DSP):能够比 CPU 更好地处理需要大量数学运算的任务。包括解压缩音乐文件等。
- 神经处理单元(NPU):用于高端智能手机,可加速机器学习(AI)任务。包括语音识别和相机处理。
- 视频编码器/解码器:处理视频文件和格式的转换,且耗能更低。
- 统一内存:允许 CPU、GPU 和其他核心快速交换信息。
这就是为什么许多人在使用 M1 Mac 进行图像和视频编辑时,都能看到速度提升的部分原因。他们执行的许多任务可以直接在专用硬件上运行。因此,价格低廉的 M1 Mac Mini 轻而易举就能够编码大型视频文件,而昂贵的 iMac 即便所有风扇都全力运转也赶不上。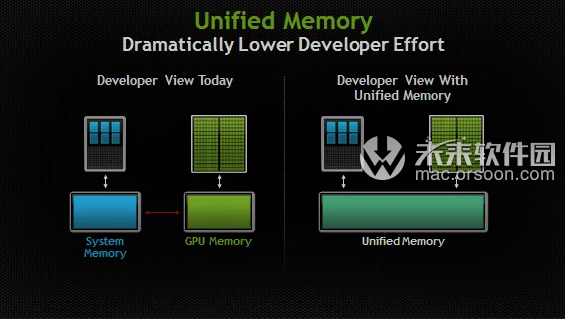 在蓝色区域内,你可以看到多个 CPU 核心可以同时访问内存,而在绿色框内,大量 GPU 核心在访问内存。你可能不太理解统一内存。共享内存与统一内存有何不同?过去,人们不是不赞成视频内存与主内存共享吗?因为这会导致性能降低。的确,共享内存确实不好。原因是 CPU 和 GPU 必须轮流访问内存。共享意味着二者要争用数据总线。简单来说,GPU 和 CPU 必须轮流使用狭窄的管道来存储或提取数据。但统一内存的情况不一样。在统一内存中,GPU 核心和 CPU 核心可以同时访问内存。因此,共享内存没有额外开销。另外,CPU 和 GPU 可以互相通知数据在内存中的位置。以前,CPU 必须将数据从主内存区域复制到 GPU 使用的区域。但在统一内存中,CPU 会告知 GPU:“我从内存地址 2430 开始放置了30MB 的多边形数据。”而 GPU 无需复制就可以使用这段内存。这意味着,由于 M1 上各种特殊的处理器都可以使用相同的内存池,并快速交换信息,因此可以大幅提升性能。
在蓝色区域内,你可以看到多个 CPU 核心可以同时访问内存,而在绿色框内,大量 GPU 核心在访问内存。你可能不太理解统一内存。共享内存与统一内存有何不同?过去,人们不是不赞成视频内存与主内存共享吗?因为这会导致性能降低。的确,共享内存确实不好。原因是 CPU 和 GPU 必须轮流访问内存。共享意味着二者要争用数据总线。简单来说,GPU 和 CPU 必须轮流使用狭窄的管道来存储或提取数据。但统一内存的情况不一样。在统一内存中,GPU 核心和 CPU 核心可以同时访问内存。因此,共享内存没有额外开销。另外,CPU 和 GPU 可以互相通知数据在内存中的位置。以前,CPU 必须将数据从主内存区域复制到 GPU 使用的区域。但在统一内存中,CPU 会告知 GPU:“我从内存地址 2430 开始放置了30MB 的多边形数据。”而 GPU 无需复制就可以使用这段内存。这意味着,由于 M1 上各种特殊的处理器都可以使用相同的内存池,并快速交换信息,因此可以大幅提升性能。
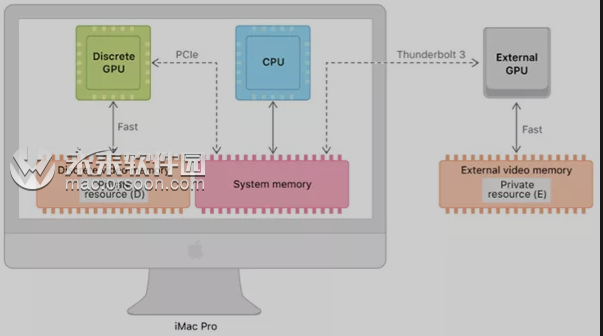
在统一内存出现之前,Mac 使用 GPU 的方式。你甚至可以选用计算机外部安装的显卡(通过 Thunderbolt 3 线安装)。有人猜测未来这种情况仍有可能出现。
为什么英特尔和 AMD 不使用相同的战略?
既然苹果的做法如此聪明,为何大家不照搬呢?从某种程度上来说,有些人确实在照抄苹果。有些 ARM 芯片制造商在专用硬件上的投资越来越多。AMD还尝试在某些芯片上安装功能更强大的GPU,并逐步采用加速处理单元(APU),向着单片系统迈进,这些处理器的CPU核心和GPU核心基本上都位于同一个芯片之上。
AMD Ryzen 加速处理单元(APU)在一块芯片上集成了 CPU 和 GPU(Radeon Vega)。但是不包含其他协同处理器、IO 控制器或统一内存。然而,还有一些重要的原因致使他们无法完全贯彻苹果的做法。单片系统本质上是在一块芯片上构建整个计算机。因此,这种做法更适合于真正的计算机制造商,比如惠普和戴尔等。我用汽车来做一个简单的类比:如果你的业务模型是制造和销售汽车发动机,那么对你来说,制造和销售整车将是一次不寻常的飞跃。相比之下,这对于 ARM 来说并不是大问题。戴尔或惠普等计算机制造商只需要购买 ARM 和其他厂商芯片的授权,就可以利用各种专用硬件制作自己的单片系统。接下来,他们将完成的设计移交给 GlobalFoundries 或台积电等半导体代工厂,这些工厂如今就在为 AMD 和苹果生产芯片。
在英特尔和 AMD 的商业模式下,我们遇到了一个很大的问题。他们的商业模式的基础是销售通用 CPU,人们只需将其插入大型 PC 主板即可。因此,计算机制造商只需从其他供应商那里购买主板、内存、CPU 和显卡,并将这些芯片集成到一个解决方案中。但是,如今的发展趋势正在迅速远离这种模式。在新的单片系统世界中,你无需组装来自不同供应商的物理组件。相反,你需要组装不同供应商的知识产权。首先,你需要从各个供应商那里购买显卡、CPU、调制解调器、IO 控制器和其他产品的设计,并将其用于内部的单片系统设计。然后,再通过某家代工厂来生产。那么,问题来了:因为英特尔、AMD 或英伟达都不会向戴尔或惠普发放知识产权许可,不会给他们机会制造自己的单片系统。当然,英特尔和 AMD 可能也会销售完整的单片系统。但是其中包含什么呢?每个 PC 制造商对单片系统所包含的内容可能都有各自的看法。英特尔、AMD、微软和 PC 制造商之间可能会出现冲突,因为这些芯片需要软件支持。对于苹果来说,这并不是什么难事,因为他们控制着所有环节。例如,他们为开发人员提供了 Core ML 库,方便他们编写机器学习代码。至于 Core ML 是在苹果的 CPU 上运行还是在 Neural Engine 上运行,并不是开发人员所关心的实现细节。
加快 CPU 运行的根本难题
因此,异构计算是 M1 芯片实现高性能的部分原因,但不是唯一的原因。M1 芯片上的通用 CPU 核心 Firestorm 确实非常快。这是 Firestorm 与过去的ARM CPU 的一个重大差异,过去的 ARM CPU 核心与 AMD 和英特尔的核心相比非常弱。然而,Firestorm 击败了大多数英特尔核心,而且几乎战胜了最快的 AMD Ryzen 核心。按照传统经验来看,这种情况并不会发生。在讨论 Firestorm 运行速度如此之快的原因之前,我们先来了解一下哪些核心理念可以真正加快 CPU 的速度。原则上,你可以结合以下两种策略来加快 CPU 的速度:
在上个世纪 80 年代,快速执行更多指令很容易。只要增加时钟频率,指令就会加速完成。一个时钟周期是计算机执行某项操作的时间。但是一个时钟周期可能不够用,因此,有时一条指令可能需要多个时钟周期才能完成,因为它由几个较小的任务组成。但是,如今我们几乎不可能再提高时钟频率了。经过人们十多年坚持不懈的努力,如今摩尔定律已经失效了。
多核与乱序处理器
并行执行大量指令的方法有两种。一种是添加更多 CPU 核心。从软件开发人员的角度来看,这就如同添加线程。每个 CPU 核心就是一个硬件线程。如果你不知道线程是什么,则可以将其视为执行任务的进程。一个拥有两个核心的 CPU可以同时执行两个单独的任务,即两个线程。而任务可以理解为存储在内存中的两个单独的程序,或者是同一个程序执行两次。每个线程都需要一些记录,例如该线程在程序指令序列中的当前位置。每个线程可以存储临时的结果,而且应该分开保存。原则上来说,处理器即便只拥有一个核心也可以运行多个线程。在这种情况下,处理器需要暂停一个线程,将当前进程保存下来,然后再切换到另一个线程。稍后再切换回去。这种做法无法带来太多性能上的提升,而且只能在某个线程需要频繁停下来等待用户输入,或网络连接速度太慢的情况才能使用。以上这些可以称为软件线程。硬件线程则意味着需要使用额外的物理硬件(例如额外的核心)来加快处理速度。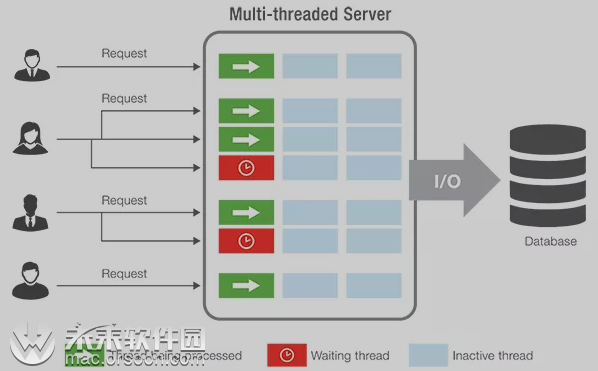
然而,问题在于,开发人员需要编写代码才能利用这一点。有一些任务(例如服务器软件)很容易做到这一点。例如单独处理每个用户,这些任务之间彼此独立,因此拥有大量核心是服务器(尤其是基于云的服务)的绝佳选择。

图:Ampere Altra Max ARM CPU,拥有 128 个核心,专为云计算而设计,多硬件线程是其优势之一。这就是为什么 Ampere 等 ARM CPU 制造商生产出的 Altra Max 等 CPU 拥有 128 个核心的原因。该芯片是专门为云计算而设计的。单个核心不需要拥有疯狂的性能,因为在云中利用好每一瓦特的功耗,处理尽可能多的并发用户才是重中之重。相比之下,苹果的情况则完全不同。苹果的产品都是单用户的设备。大量线程并不是他们的优势。他们的设备可用于玩游戏、编辑视频、开发等。他们希望台式机拥有精美的、响应速度超快的图像和动画。桌面软件通常不会利用很多核心。例如 8 个核心对电脑游戏来说就足够了,128 个核心完全是浪费。相反,这些软件需要少量更强大的核心。接下来我们要讲的内容很有意思。乱序执行是一种能够并行执行更多指令、但不需要多线程的方式。开发人员无需专门编写软件即可享受乱序执行的优势。从开发人员的角度来看,似乎每个核心的运行速度都加快了。为了理解其中的工作原理,我们先来了解一些内存方面的知识。请求位于某个特定内存位置中的数据会很慢。但是,获取 1 个字节的延迟与获取 128 个字节的延迟并没有区别。数据是通过数据总线发送的。你可以将数据总线视为连接内存与 CPU 各个部分的一条通道或管道,数据正是通过这条管道传输的。实际上,数据总线就是一些可以导电的铜线。如果数据总线足够宽,则可以同时获取多个字节。因此,CPU 一次可以获取整块指令,但是这些指令必须逐条执行。现代微处理器采用了乱序执行。这意味着,这些处理器能够快速分析指令缓冲区,并检查哪些指令之间有相互依赖关系。我们举一个简单的例子:
01: mul r1, r2, r3 / / r1 ← r2 × r3
02: add r4, r1, 5 // r4 ← r1 + 5
03: add r6, r2, 1 // r6 ← r2 + 1
乘法是相对较慢的操作,假设它需要多个时钟周期才能执行完成。这时,第二条指令就需要等待,因为它需要知道放入 r1 寄存器的结果。然而,第三条指令(03 行)并不依赖于前面的计算结果。因此,乱序处理器可以开始并行计算这条指令。但实际情况是,处理器每时每刻都需要处理成百上千的指令,而 CPU 能够找出这些指令之间的所有依赖关系。它会分析指令,检查每条指令的输入,看一看这些输入是否依赖于其他一个或多个指令的输出。这里的输入和输出指的是包含先前计算结果的寄存器。例如,指令 add r4, r1, 5 的输入 r1 依赖于前一个指令 mul r1, r2, r3 的结果。这些依赖关系链接在一起就可以形成关系图,而CPU可以使用这个图进行处理。图中的节点就是指令,而边就是连接这些指令的寄存器。CPU 可以分析这样的节点图,并确定它可以并行执行哪些指令,以及在执行哪个指令之前需要等待多个相关的计算结果。尽管许多指令都可以提前完成,但我们不能将它们作为最终的结果。我们不能提交这些指令的执行结果,因为它们的执行顺序不正确。而在用户看来,这些指令都是按照发行的顺序执行的。就像栈一样,CPU 将从顶部弹出完成的指令,直到遇到一条未完成的指令。虽然上述说明不够充分,但希望能让你有大致的了解。基本上,你可以选择让程序员实现并行,或者让 CPU 假装一切都是单线程执行,但幕后采用乱序执行。M1 芯片上的 Firestorm 核心正是借助了出色的乱序执行功能才变得如此强大。事实上,它比英特尔或 AMD 的任何产品都要强大,甚至可能超过了主流市场上的任何其他产品。
为什么 AMD 和英特尔的乱序执行不如 M1?
前面在解释乱序执行的时候,我略过了一些重要的细节,这里需要再说明一下,否则就很难理解为什么苹果能领先,而且英特尔和 AMD 很难超越。前面说的“栈”的真正名称叫做“重排序缓冲”(Re-Order Buffer,ROB),它并不包括普通的机器代码指令。其中的内容并不是 CPU 从内存中获取并执行的指令,后者属于 CPU 指令架构(ISA),是那些我们称为 x86、ARM、PowerPC 等的指令。但是在内部,CPU 执行的是一系列完全不同的指令集,这些指令对于程序员是不可见的。我们称之为微指令(简称 μops)。ROB 中包含的都是微指令。由于 CPU 尽一切努力并行执行指令,所以 ROB 的这种做法更实际一些。原因是,微指令非常宽(包含更多比特),可能包含各种元信息。而 ARM 或 x86指令集中无法添加这么多信息,因为:- 会暴露 CPU 的内部工作原理,是否有乱序执行单元,是否有寄存器重命名等各种细节;
你可以将这个过程理解成写程序。你有一个公开的 API,需要保持稳定,供所有人使用。这就是 ARM、x86、PowerPC、MIPS等指令集。而微指令是那些用来实现公开 API 的私有 API。而且,微指令通常更容易被 CPU 处理。为什么?因为每条指令只做一件非常容易的任务。正常的 ISA 指令可以非常复杂,可能会引发一系列操作,因此需要翻译成多条微指令。CISCCPU 通常别无选择,只能使用微指令,否则复杂的 CISC 指令会让流水线和乱序执行几乎无法实现。而 RISC CPU 还有别的选择。例如,小型的 ARM CPU 完全不使用微指令。但这也意味着它们没办法实现乱序执行之类的操作。但你可能会问,你说这些有什么关系吗?为什么需要知道这些细节,才能理解为何苹果超越了 AMD 和英特尔呢?这是因为,芯片的运行速度取决于填充 ROB 的速度以及使用的微指令数量。填充得越快、越多,并行获取指令的可能性就越大,因此能够提高性能。机器指令由指令解码器拆分成微指令。如果有多个解码器,就能并行地拆分更多指令,从而更快地填充 ROB。这里就是苹果和其他厂商出现重大差别的地方。最次的英特尔和和 AMD 的微处理器核心只有四个解码器,意味着它们可以同时解码四条指令。但苹果有 8 个解码器。不仅如此,苹果的 ROB 是英特尔和 AMD 的三倍大小,可以容纳三倍的指令。没有任何主流芯片制造商的 CPU 中有这么多解码器。
为什么英特尔和 AMD 不能添加更多的指令解码器?
下面,我们来看一看 RISC 的优势,以及 M1 Firestorm 核心采用的 ARM RISC 架构有哪些出色表现。你知道,在 x86 中,指令长度约为 1~15 字节。而在 RISC 上指令是固定长度。这有什么关系?如果每条指令的长度都一样,那么将一个字节流分割,并行发送给 8 个不同的解码器就非常容易。但是在 x86 CPU 上,解码器并不知道下一条指令从什么地方开始。它必须按顺序分析每一条指令才能得知具体的长度。英特尔和 AMD 采取暴力的方式来解决这个问题,即在每个可能的开始位置尝试解码。也就是说,许多错误的猜测就只能抛弃。这就导致解码器变得非常复杂,因此很难添加更多的解码器。但这对于苹果不是问题,他们可以很容易地添加更多解码器。实际上,添加更多解码器会带来更多问题,因此对于 AMD 而言,4 个解码器就是上限了。所以,M1 Firestorm 核心能在同一时钟频率下产生比 AMD 和英特尔 CPU 多一倍的指令。有人会说,可以将 CISC 拆分成多条微指令,增加指令的密度,这样解码一条x86 指令就可以达到解码两条 ARM 指令的效果。但实际情况并非如此。高度优化的x86代码很少使用复杂的 CISC 指令,甚至看上去更像 RISC。但这对英特尔和 AMD 并没有什么用,因为即使 15 字节的指令非常罕见,解码器也必须处理它们。这种复杂性成为了 AMD 和英特尔添加更多解码器的阻碍。
但 AMD 的 Zen3 核心更快吧?
据我所知,从性能的角度来看,最新的 AMD CPU 核心 Zen3 比 Firestorm 核心稍稍快一些。但这只是因为 Zen3 核心的时钟是 5GHz,而 Firestorm 核心的时钟是 3.2GHz。尽管 Zen3 的时钟频率超出了 60%,但性能只不过比Firestorm 快了一点点。那么为什么苹果不提高时钟频率呢?因为更高的时钟频率会增加芯片发热。这是苹果的主要卖点。与英特尔和 AMD 不同,他们的电脑很少需要散热。所以本质上可以说,Firestorm 核心实际上超过了 Zen3 核心。Zen3 依然能与之一战,只是因为它的能耗更高,发热量也更大。苹果并选择这条路。如果苹果需要更高的性能,那么他们会添加更多的核心。这样就能在保持低功率的条件下提高性能。
未来的发展
- 由于旧的x86 CISC指令集的负担,很难提高乱序执行性能
但这并不意味着穷途末路。他们仍然可以通过提高时钟频率、使用更好的散热、添加更多核心、提高CPU缓存等方式。但每一项都有缺点。英特尔的处境最糟糕,因为他们的核心数已经不及 Firestorm,而且他们的单片系统解决方案中的 GPU 也更弱。添加更多核心的问题在于,对于一般的桌面负载而言,过多核心带来的收益很低。当然对于服务器而言,核心数多多益善。但是,亚马逊、Ampere 等公司都在研究 128 核心的 CPU。这就意味着英特尔和 AMD 即将面临双重夹击。但对于 AMD 和英特尔来说,幸运的是,苹果并没有在市场上销售芯片。所以PC 用户别无选择。PC 用户可能会转而使用苹果,但毕竟这是一个缓慢的过程。切换日常使用的平台并不是一蹴而就的事情。但对于口袋里有钱、没有太多平台依赖的年轻人来说,以后会越来越多地选择苹果,从而提高苹果在高端市场的占有率,最终会提高苹果在整个PC市场的占有率。
网友评论
M1 之所以如此之快并不是因为技术好,而是因为苹果堆积了很多硬件。M1 非常宽(8 个解码器),还有很多执行单元。它的重排序缓冲有 630 之深,拥有***的缓存,还有大量的内存带宽。非常强悍的芯片,设计也非常平衡。 另外,这并不是什么新技术。苹果的 A 系列芯片每年都在逐步提升。只不过没人相信手机上用的芯片能超过笔记本电脑的芯片。
好啦!以上就是今天所述内容,想了解更多Mac知识的小伙伴们关注‘未来软件园’。








