Text Extractor for Mac可帮助您将扫描的PDF文档,数字图像转换为可搜索和可编辑的文本内容。它可以通过先进的OCR(光学字符识别)技术消除您的重新输入工作,该技术可以准确地识别图像中的文本并有效地提取文本内容。接下来小编为大家带来Text Extractor for Mac使用教程,感兴趣的朋友快跟着小编一起来看看吧!
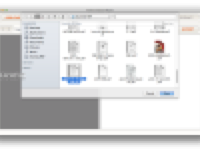
第1步:打开PDF文件 - 点击“打开文件”按钮,查找器将在应用程序中向下滑动,从本地磁盘中选择图像或PDF文件 步骤2:OCR选项 - 打开OCR,然后从下拉列表中选择正确的文档语言。如果您的PDF文件不是扫描文件,请关闭OCR。
步骤2:OCR选项 - 打开OCR,然后从下拉列表中选择正确的文档语言。如果您的PDF文件不是扫描文件,请关闭OCR。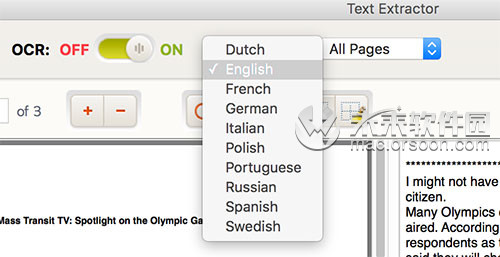 第3步:开始数据提取 - 单击右上角的“提取”按钮,将开始文本提取。
第3步:开始数据提取 - 单击右上角的“提取”按钮,将开始文本提取。 第4步:保存提取的文本内容 - 您可以在应用程序的右侧看到提取的文本,您可以将原始图像或扫描的PDF与提取的文本进行比较,执行语法和拼写检查,或直接在文本编辑器。如果一切正常,请复制到剪贴板,然后将提取的文本粘贴到其他应用程序,或将内容导出到txt文件。
第4步:保存提取的文本内容 - 您可以在应用程序的右侧看到提取的文本,您可以将原始图像或扫描的PDF与提取的文本进行比较,执行语法和拼写检查,或直接在文本编辑器。如果一切正常,请复制到剪贴板,然后将提取的文本粘贴到其他应用程序,或将内容导出到txt文件。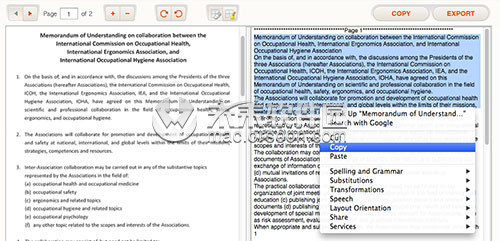 以上就是小编为大家带来的“Text Extractor for Mac使用教程”的全部内容,希望对大家有所帮助!
以上就是小编为大家带来的“Text Extractor for Mac使用教程”的全部内容,希望对大家有所帮助!