Text Extractor f如何在Mac(OCR)上从PDF和图像中提取文本?Text Extractor for Mac是一款易于使用的OCR应用程序。借助Text Extractor for Mac提供的高级OCR功能,您可以快速从扫描的纸质文档和图像文件中提取文本内容,将其转换为可编辑和可搜索的文本内容。接下来小编为大家带来具体操作步骤,感兴趣的朋友千万不要错过!
1.启动应用程序并打开文件
打开Finder>应用程序,然后单击“文本提取器”图标。界面出现后,单击“打开文件”按钮。然后,您可以从下拉查找器窗口中选择要执行提取的文件。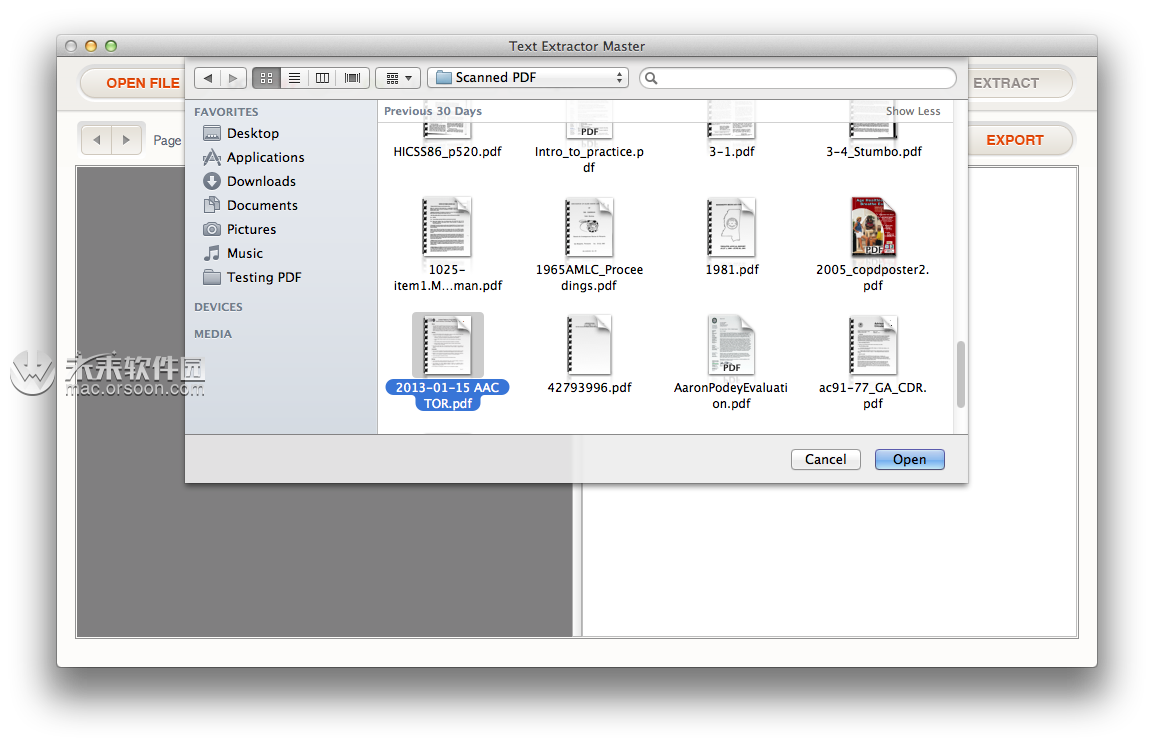 支持的输入文件格式:
支持的输入文件格式:
PDF文件(.pdf)
图像格式:png,jpeg,jpg,tif,tiff,bmp,gif。
2.选择输出和OCR选项
如果导入的文件不是扫描的文件或图像,则无需启用OCR选项并选择文档语言。
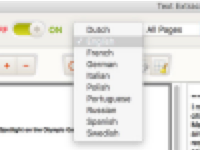
如果导入图像文件或扫描的PDF文件,请启用OCR,选择正确的文档语言。
提示:如何区分扫描的PDF文件与普通文件>>
您可以选择转换所有页面或当前页面。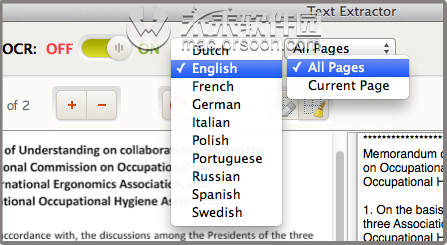 3.开始提取
3.开始提取
点击“提取”按钮,转换将开始。 4.使用提取的文本内容
4.使用提取的文本内容
提取过程完成后,您将看到输出区域中的文本内容可用。您可以直接在输出区域内编辑内容,将文本内容复制到剪贴板,或将其作为纯文本文件(.txt)提取。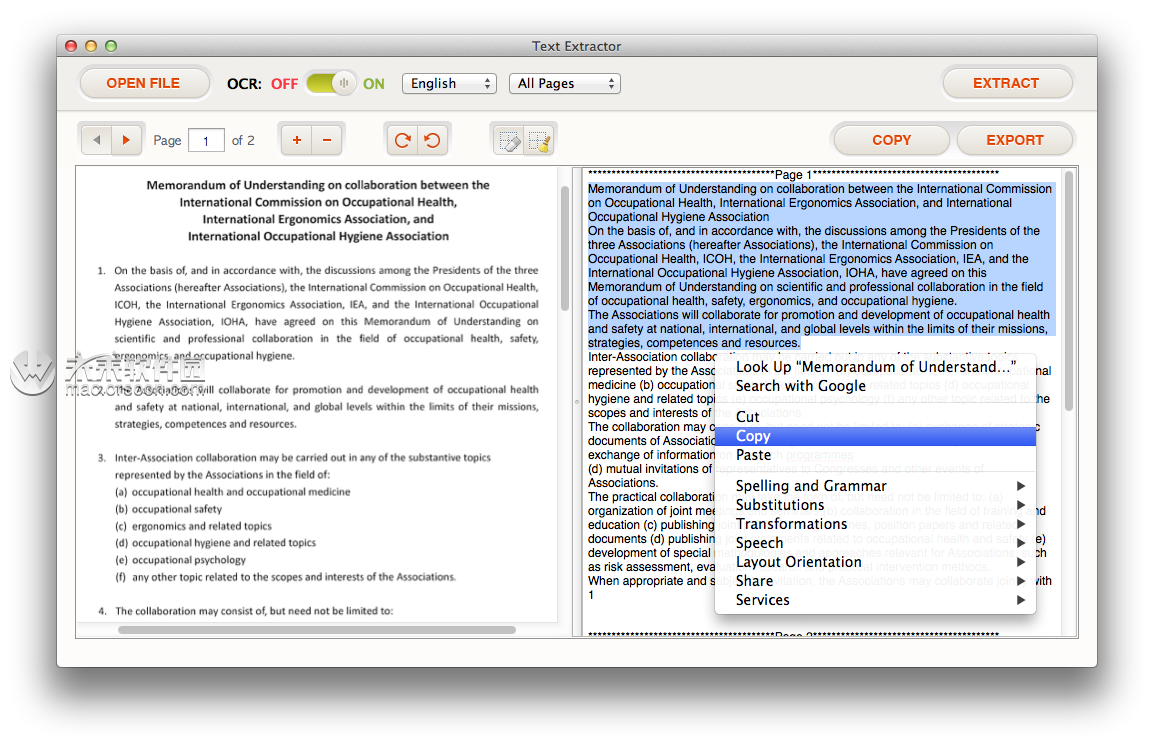 提高转换质量和生产力的高级步骤:
提高转换质量和生产力的高级步骤:
1.提高转换质量
(1)提高图像分辨率
OCR转换的准确性取决于原始PDF的质量。可能无法准确识别文档图像质量差和文档偏斜。
图像应至少为300 dpi,对于字体较小的文档,建议使用600 dpi。或者文本将粘在一起,OCR很难准确识别这些文本。
OCR可以更好地处理具有白色背景和黑色文本内容的文档。
(2)将页面旋转到正确的方向
PDF文档或图像必须正面朝上。
(3)选择正确的文档语言
选择正确的文档语言非常重要,例如,如果您的PDF文件是俄语,但您选择英语作为识别语言,结果将无法正确。
(4)指出图片区域
如果您不想从图片区域或导入文件的任何特定区域中提取文本,请拖动以指出这些区域。
2.运行拼写检查以快速修复错误识别
OCR不是一件容易的事,一些相似的字符,例如'e'和'c','l','i'和'!' 可能无法正确识别。运行拼写检查可以快速找到这些错误并快速纠正。
右键单击输出区域,选择“Spelling and Grammar” - >“Show Spelling and Grammar”。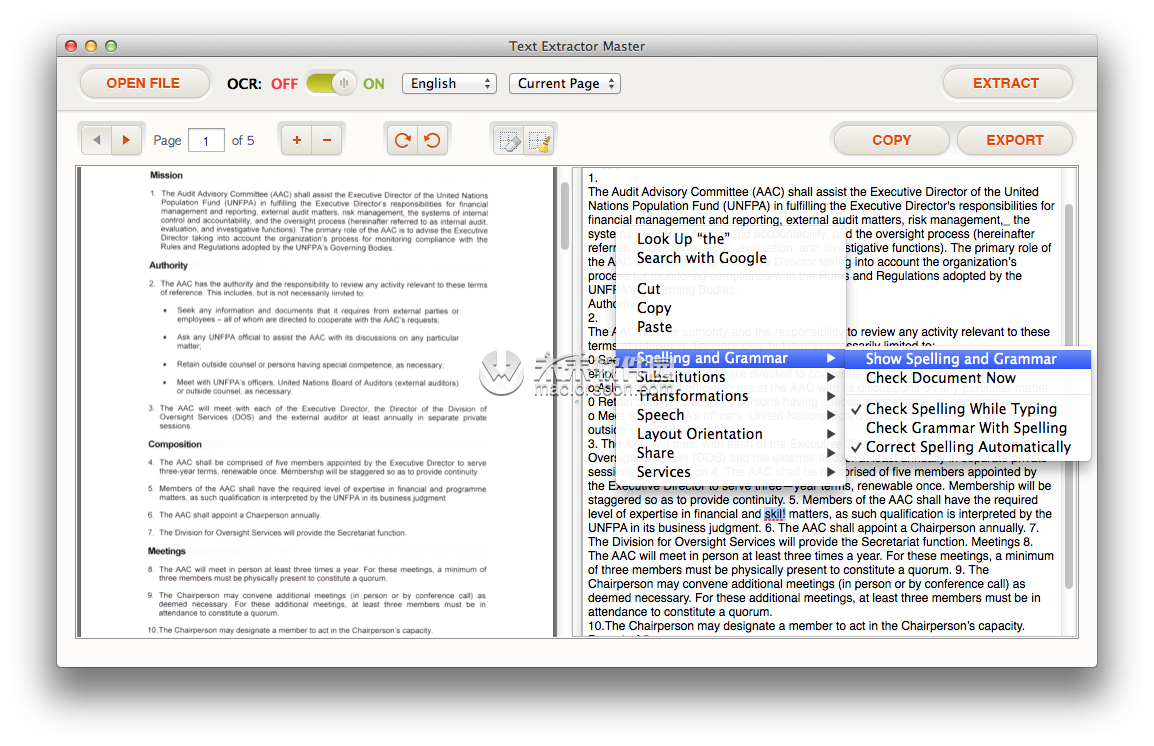 将弹出一个窗口。例如,'技能'被错误地识别为'Skil!',运行拼写检查以快速发现此错误,从推荐中选择正确的一个并单击“更改”按钮。
将弹出一个窗口。例如,'技能'被错误地识别为'Skil!',运行拼写检查以快速发现此错误,从推荐中选择正确的一个并单击“更改”按钮。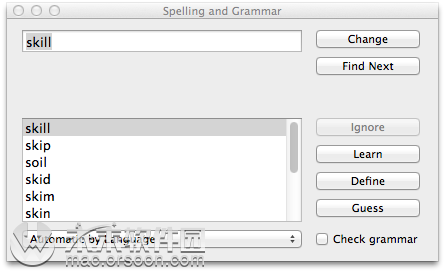
以上就是小编为大家带来的“Text Extractor如何在Mac上从PDF和图像中提取文本?”的全部内容,希望对大家有所帮助!